Mining Text from PDF Files, Part 3: PDF with an Image
Intro
I wanted to find out how to mine text from PDF files with R. I’m experimenting with different formats, the previous ones having been text and tables. In this last one I will extract text that’s in an image that’s inside a PDF file.
I’m assuming you’re using RStudio as your IDE (Integrated Development Environment). I’m sure most of this can be done with using something else as well.
tesseract and magick in action
For this last PDF experiment, I’m using this awesome package called tesseract. It’s a powerful optical character recognition (OCR) engine that supports over 100 languages. Still, a disclaimer is in order. According to the package documentation:
Keep in mind that OCR (pattern recognition in general) is a very difficult problem for computers. Results will rarely be perfect and the accuracy rapidly decreases with the quality of the input image. But if you can get your input images to reasonable quality, Tesseract can often help to extract most of the text from the image.
In order to get the most out of tesseract, we’ll also be trying out another cool package called magick. It has a lot of powerful features beyond our scope today and if you’re interested in image prosessing in general, it’s definitely worth checking out.
1. Let’s get ready
Before we go any further, I’m going to load the packages we’ll be needing today:
library(tesseract)
# The main package for this operation
library(magick)
# Used for image pre-processing when needed
library(pdftools)
# Not the main 'character' today, but we still need this one in the first example
library(tidyverse)
# Prerequisite to everything
library(writexl)
# My go-to package for writing Excel filesI’ll also show you the raw material. If you’d like to try this at home, you can save the PDF file shown below. What we’re looking at here is (Spotify’s weekly top 100 chart for Finland (2021-05-14 - 2021-05-21), as it is on the web page. I will be using a sample of the first 18 tracks.
Immediately we can detect some potential trouble ahead with this one. There’s a lot of unnecessary information (the thumbnails, the markers showing whether the song has gone up or down on the list etc.) and the text for artist names and streams is very faint (at least compared to the track names).
fig. 1 - The raw material
2. Read in the PDF file with pdftools
To begin, let’s read in the pdf file using pdftools:
pdf_with_image_1 <- "index_files/pdf_with_image_1.pdf"
png_with_image_1 <- pdf_convert(pdf_with_image_1, dpi = 600, format = "png")
## Converting page 1 to pdf_with_image_1_1.png... done!3. ‘Read’ the image with tesseract
Let’s see what our baseline is without any pre-prepping.
eng <- tesseract("eng")
text_from_image_1 <- ocr(png_with_image_1, engine = eng)
cat(text_from_image_1)
## RA 7 4G
## ~ MONTERO (Call Me By Your Name) 3
## gg Ms ~ Dark Side © Tal :
## BN es ye
## a - © Piilotan mun kyyneleet aloo He
## or 7 ~ Kiss Me More (feat. SZA) by Dc :
## oS Life (Sun luo) =dos, BEl
## fA ~ Astronaut In The Ocean by \Viasked VVolf
## D> 7 aterm a
## $ Hyvat hautajaiset by ,
## [Oa
## Ne voi liittyy (feat. BIZI) scr
## Bs ~ Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit by Ritc EL
## —“7 Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio Foreign & Darkoo]
## ame latte lia eae IP ae) (eb athan Evans
## i 4 ~ Levitating (feat. DaBaby) by Dua Lip:
## . ) ~ Prinsessa by Ett
## D> Hei rakas by 85
## ib 7» Peaches (feat. Daniel Caesar & Giveon) istin Bie
## ¥. ; 3 ~» Kaipaan sua (feat. Boyat & Samuli Heimo) > SalatOkay, not exactly what we would’ve hoped to see, but not as bad as I feared. 15 out of 18 track names are there and parts of the artist names as well. But a lot of extra noise too. Let’s take care of that first.
Let’s see what we can do with a slightly cropped version of the same image.
4. Crop the image with magick
First, we need to know the width of the original image to know what we’re working with here.
At this point, we’re going to leave pdftools behind and use only magick (and tesseract after the pre-processing is done).
So, let’s read in the pdf with image_read_pdf() and look at the metadata:
png_1 <- image_read_pdf("index_files/pdf_with_image_1.pdf")
print(png_1)
## # A tibble: 1 x 7
## format width height colorspace matte filesize density
## <chr> <int> <int> <chr> <lgl> <int> <chr>
## 1 PNG 3300 2550 sRGB TRUE 0 300x300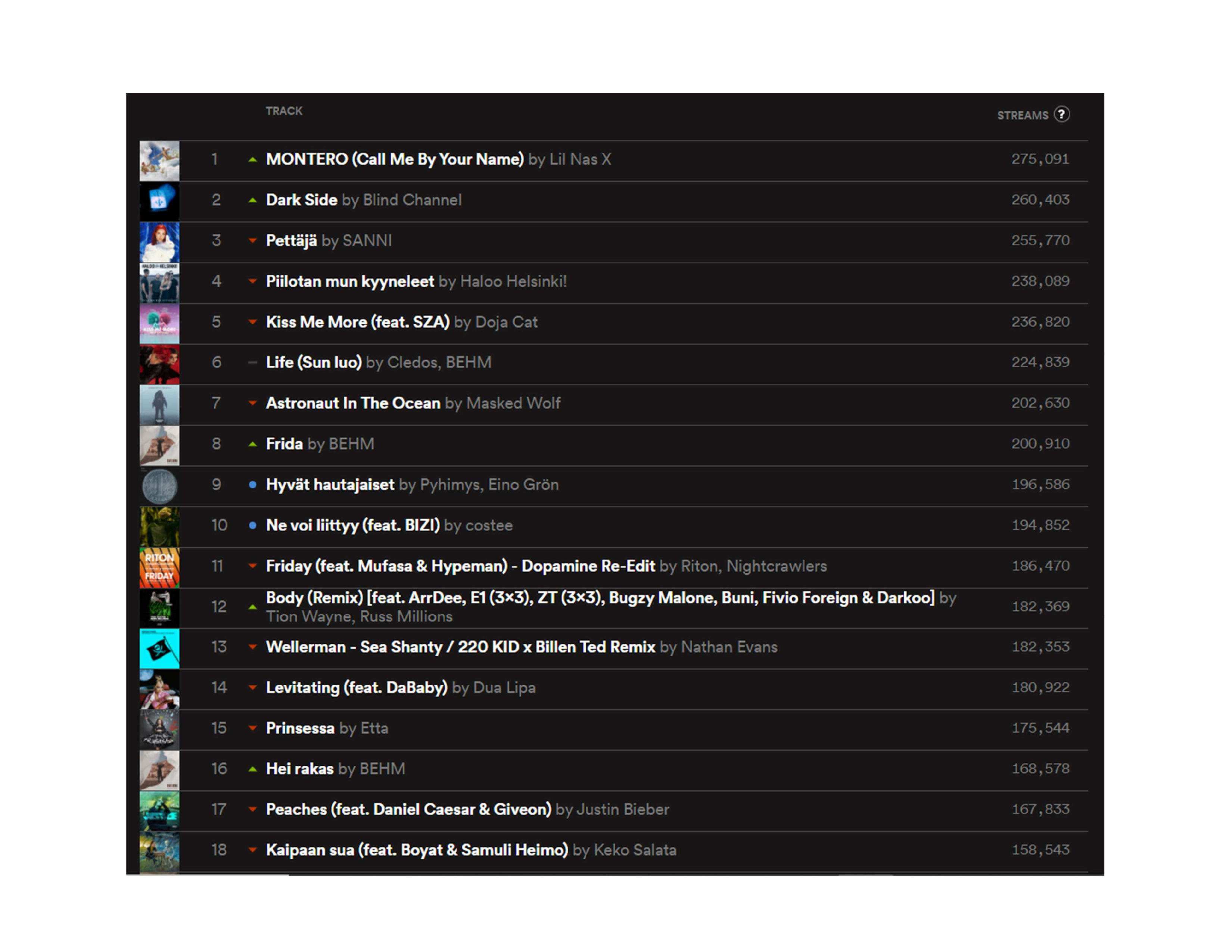
We can see that the image’s width is 3300 (pixels). At the moment that’s the only piece of information we’re interested in.
So, what if we take away some amount of pixels from the left, so that we’re left with just the text elements.
(Just like in all the cooking shows on TV, I’ve omitted the part where I tested with different widths to come up with the one that I was happy with.)
But now that we know that we want to crop away 700 pixels from the left, we just have to insert the target width (2600) x target height (2550) + crop position from the left (700) to image_crop():
png_2 <- png_1 %>% image_crop("2600x2550+700")
print(png_2)
## # A tibble: 1 x 7
## format width height colorspace matte filesize density
## <chr> <int> <int> <chr> <lgl> <int> <chr>
## 1 PNG 2600 2550 sRGB TRUE 0 300x300
Nice and tidy cropping, isn’t it! What do you think, did that help with the actual text mining? Only one way to find out!
5. ‘Read’ the cropped image with tesseract
# eng <- tesseract("eng") <-- we don't need to run this again
text_from_image_2 <- ocr(png_2, engine = eng)
cat(text_from_image_2)
## - -
## MONTERO (Call Me By Your Name) by Li! Nz
##
## Dla @-) (+ {Beles
##
## PTET :
## Piilotan mun kyyneleet by Haloo He
##
## Kiss Me More (feat. SZA) by [ oF}
##
## Life (Sun luo) edos, BE
##
## Astronaut In The Ocean by Masked Wolf
##
## Frida by BEF
##
## Hyvat hautajaiset by F ar6n
##
## Ne voi liittyy (feat. BIZI) stee
##
## Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit by Ritc eee Mae
##
## Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio Foreign & Darkoo]
##
## Meee Bit lis ear nen PD astm Crem cuih at aE
##
## Levitating (feat. DaBaby) by Dua Lip=
##
## Prinsessa by Ett<
##
## a (0 e- | < eeslale
##
## Peaches (feat. Daniel Caesar & Giveon) ustin Bie
##
## Kaipaan sua (feat. Boyat & Samuli Heimo) 2ko SalatInteresting! As the Finnish saying goes, “That doesn’t take us to the moon, yet”. But we did get rid of the extra noise. A crucial first step.
However, now only 14 out of 18 track names are correct. So we lost one track name in the process. Let’s not worry too much about that at the moment, though.
I do wonder if we could do some more magick tricks with the image and see if that helps at all with the recognition.
We’ll be using some of the methods mentioned in the documentation for Tesseract (the algorithm, not the R package with a lower case r).
6. Use magick to make the image more machine friendly
The first thing to try out is to make a negative version of the image. Why? Because I’m thinking that the grey text would perhaps be easier to distinguish from a white background than from a black one.
# Negating the image
png_2_negated <- png_2 %>%
image_negate()
# Using that negated image to 'read' the text
png_2_negated %>%
ocr(engine = eng) %>%
cat()
## = G
## MONTERO (Call Me By Your Name) by Li! Nz
##
## Dark Side by £
##
## Pettaja ;
## Piilotan mun kyyneleet by Haloo He
##
## Kiss Me More (feat. SZA) by [ Sat
##
## Life (Sun luo) edos, BE
##
## Astronaut In The Ocean by Masked Wolf
##
## Frida by BEF
##
## Hyvat hautajaiset by F ar6n
##
## Ne voi liittyy (feat. BIZI) stee
##
## Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit by Ritc ghtcrawlers
##
## Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio Foreign & Darkoo]
##
## Wellerman - Sea Shanty / 220 KID x Billen Ted Remix at Eve
##
## Levitating (feat. DaBaby) by Dua Lip=
##
## Prinsessa by Ett<
##
## Hei rakas by BEF
##
## Peaches (feat. Daniel Caesar & Giveon) ustin Bie
##
## Kaipaan sua (feat. Boyat & Samuli Heimo) 2ko Salat
# Printing out the negated image
png_2_negated
A great start! That one thing lead to us having all of the track names there. Let’s then convert the image to Grayscale to see if we could get more information out of it:
# Grayscaling the image
png_2_grayscale <- png_2_negated %>%
image_convert(type = "Grayscale")
# Using that grayscaled image to 'read' the text
png_2_grayscale %>%
ocr(engine = eng) %>%
cat()
## STRE ?
## MONTERO (Call Me By Your Name)
## Dark Side by Blinc :
## Pettaja
## Piilotan mun kyyneleet
## Kiss Me More (feat. SZA) by Doja C
## Life (Sun luo) 2dos
## Astronaut In The Ocean
## Frida by BE}
## Hyvat hautajaiset by F s, Ein
## Ne voi liittyy (feat. BIZ!) stee
## Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit ‘: ghtc
## Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio Foreign & Darkoo]
## Wellerman - Sea Shanty / 220 KID x Billen Ted Remix athan E
## Levitating (feat. DaBaby) ua Lipz
## Prinsessa
## Hei rakas by BE
## Peaches (feat. Daniel Caesar & Giveon)
## Kaipaan sua (feat. Boyat & Samuli Heimo) 2ko Sala
# Printing out the grayscaled image
png_2_grayscale
Some conflicting results there. Grayscaling helped with some rows, but hindered with others. Let’s keep going and see if additional image transformations will be of use.
How about resizing? (CAUTION! Making the image too large will take a long while for the computer to process. Why do I know that? I’m sure you can guess the reason…):
# Resizing the image
png_2_resized <- png_2_grayscale %>%
image_resize("4000x")
# Using that resized image to 'read' the text
png_2_resized %>%
ocr(engine = eng) %>%
cat()
## STRE ?
## MONTERO (Call Me By Your Name)
## Dark Side by § :
## Pettaja
## Piilotan mun kyyneleet by Haloo Hels
## Kiss Me More (feat. SZA) by Doja Cat
## Life (Sun luo) Jos, BE
## Astronaut In The Ocean :
## Frida by BE
## Hyvat hautajaiset « BE aror
## Ne voi liittyy (feat. BIZI) :
## Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit yhtcr
## Body (Remix) [feat. ArrDee, E1(3x3), ZT (3x3), Bugzy Malone, Buni, Fivio Foreign & Darkoo] &:
## Wellerman - Sea Shanty / 220 KID x Billen Ted Remix athan Ev
## Levitating (feat. DaBaby) 4a Lipz
## Prinsessa by Ett<
## Hei rakas by BE
## Peaches (feat. Daniel Caesar & Giveon) : 3
## Kaipaan sua (feat. Boyat & Samuli Heimo) ate
# Printing out the resized image
png_2_resized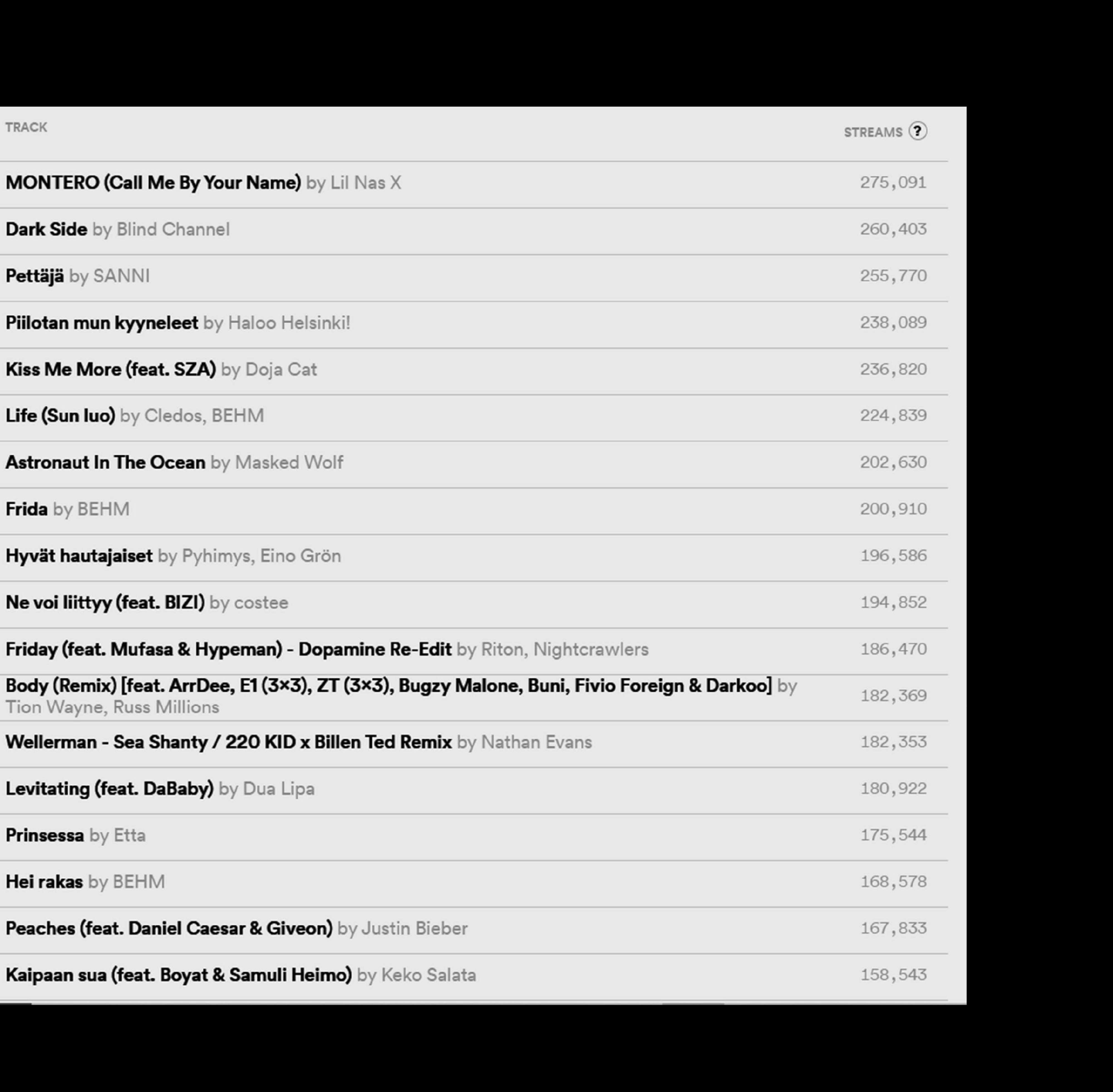
Next up, trimming the margins.
# Trimming the image
png_2_trimmed <- png_2_resized %>%
image_trim(fuzz = 80)
# The fuzz parameter allows for the fill to cross for adjacent pixels with similarish colors. Its value must be between 0 and 256^2 specifying the max geometric distance between colors to be considered equal.
# Using that trimmed image to 'read' the text
png_2_trimmed %>%
ocr(engine = eng) %>%
cat()
## TRACK STREAMS (?
## MONTERO (Call Me By Your Name) by Li! Nas x 275,091
## Dark Side by Blind Channe! 260.403
## Pettaja by SANN| 255,770
## Piilotan mun kyyneleet by Haloo Helsinki! 238,089
## Kiss Me More (feat. SZA) by Doja Cat 236,820
## Life (Sun luo) by Cledos, BEHM 224,839
## Astronaut In The Ocean by \Viasked VVolf 202,630
## Frida by BEHM 200,910
## Hyvat hautajaiset by Pyhimys, Eino Grén 196 , 586
## Ne voi liittyy (feat. BIZI) by costee 194,852
## Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit by Riton, Nightcrawilers 186,470
## Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio Foreign & Darkoo] by eS
## Tion Wayne, Russ Millions aes
##
## Wellerman - Sea Shanty / 220 KID x Billen Ted Remix by Nathan Evans 182,353
## Levitating (feat. DaBaby) by Dua Lipa 180 , 922
## Prinsessa by Etta 175.544
## Hei rakas by BEH!V/ 168,578
## Peaches (feat. Daniel Caesar & Giveon) by Justin Bieber 167 .833
## Kaipaan sua (feat. Boyat & Samuli Heimo) by Keko Salate 158 , 543
# Printing out the trimmed image
png_2_trimmed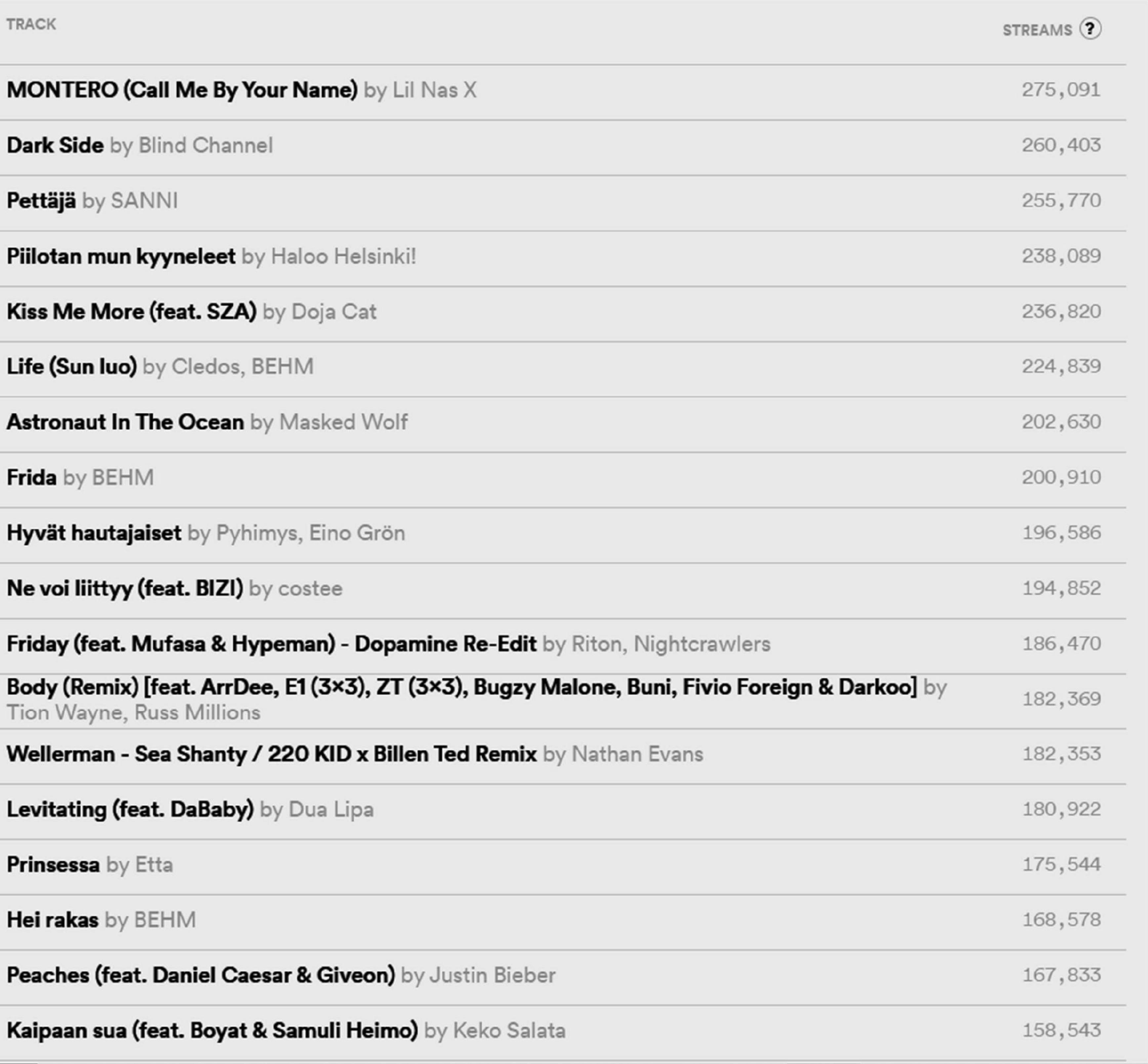
Wow! Just by removing the extra margins, we were able to get most of the data to appear. One interesting thing to try would be to see whether you could just use that image_trim() alone and reach the same place without all the other steps. I suggest you try that!
Also, I could spend more time analysing the different combinations of the steps we’ve tried so far and some steps we have yet to try. However, to be able to release this blog post, I must stop somewhere.
So, for now, this will do. The improvement from the beginning to here is really impressive! So, let’s finish this by doing some cleanup.
7. Create a character vector, split it into a list and then convert it to a tibble
# Use tesseract to make a character vector and then split it into a list
png_2_list <- png_2_trimmed %>%
ocr(engine = eng) %>%
strsplit(split = "\n")
# Unlist that list and convert it to a tibble
png_2_tbl <- as_tibble(unlist(png_2_list))
png_2_tbl
## # A tibble: 21 x 1
## value
## <chr>
## 1 "TRACK STREAMS (?"
## 2 "MONTERO (Call Me By Your Name) by Li! Nas x 275,091"
## 3 "Dark Side by Blind Channe! 260.403"
## 4 "Pettaja by SANN| 255,770"
## 5 "Piilotan mun kyyneleet by Haloo Helsinki! 238,089"
## 6 "Kiss Me More (feat. SZA) by Doja Cat 236,820"
## 7 "Life (Sun luo) by Cledos, BEHM 224,839"
## 8 "Astronaut In The Ocean by \\Viasked VVolf 202,630"
## 9 "Frida by BEHM 200,910"
## 10 "Hyvat hautajaiset by Pyhimys, Eino Grén 196 , 586"
## # ... with 11 more rowsFrom here it’s pretty straightforward to get to the cleaned excel file. We will have to make some adjustments that are quite manual, so this wouldn’t do if we had a bunch of these files to extract text from.
Still, cleaning up the data does have some interesting steps and is always good practice, so, without further ado, let’s do this!
8. Remove first row and add the missing value manually to empty row
We won’t be needing that “TRACK STREAMS (?” text, so let’s get rid of it with slice(). Also, for the next steps involving regex to work, we need to insert the missing value and we’ll insert it on row 14 that is conveniently empty.
png_2_filtered_tbl <- png_2_tbl %>%
slice(-1) # Note to self and others: slice(n) to keep the nth row, slice(-n) to get rid of it
png_2_filtered_tbl[14, 1] <- " 182,369" # that empty character in front of the value is there on purpose... it will come in handy later with regex
png_2_filtered_tbl
## # A tibble: 20 x 1
## value
## <chr>
## 1 "MONTERO (Call Me By Your Name) by Li! Nas x 275,091"
## 2 "Dark Side by Blind Channe! 260.403"
## 3 "Pettaja by SANN| 255,770"
## 4 "Piilotan mun kyyneleet by Haloo Helsinki! 238,089"
## 5 "Kiss Me More (feat. SZA) by Doja Cat 236,820"
## 6 "Life (Sun luo) by Cledos, BEHM 224,839"
## 7 "Astronaut In The Ocean by \\Viasked VVolf 202,630"
## 8 "Frida by BEHM 200,910"
## 9 "Hyvat hautajaiset by Pyhimys, Eino Grén 196 , 586"
## 10 "Ne voi liittyy (feat. BIZI) by costee 194,852"
## 11 "Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit by Riton, Nightcrawilers~
## 12 "Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio F~
## 13 "Tion Wayne, Russ Millions aes"
## 14 " 182,369"
## 15 "Wellerman - Sea Shanty / 220 KID x Billen Ted Remix by Nathan Evans 182,353"
## 16 "Levitating (feat. DaBaby) by Dua Lipa 180 , 922"
## 17 "Prinsessa by Etta 175.544"
## 18 "Hei rakas by BEH!V/ 168,578"
## 19 "Peaches (feat. Daniel Caesar & Giveon) by Justin Bieber 167 .833"
## 20 "Kaipaan sua (feat. Boyat & Samuli Heimo) by Keko Salate 158 , 543"9. Merge rows with the help of unpivotr
In the previous post we used janitor to help with the data cleanup. This time we’ll use another nice little package called unpivotr.
And again, since we only need it this once, we might as well call it writing ‘package::function()’ instead of library(package) and function() separately.
png_2_merged_tbl <- unpivotr::merge_rows(
unpivotr::as_cells(png_2_filtered_tbl),
rows = 12:14,
chr) %>%
arrange(row) %>% # arrange is needed to get the rows in right order for later
select(chr) # after merge_rows and as_cells we need this select, otherwise there would be three other columns to worry about
png_2_merged_tbl
## # A tibble: 18 x 1
## chr
## <chr>
## 1 "MONTERO (Call Me By Your Name) by Li! Nas x 275,091"
## 2 "Dark Side by Blind Channe! 260.403"
## 3 "Pettaja by SANN| 255,770"
## 4 "Piilotan mun kyyneleet by Haloo Helsinki! 238,089"
## 5 "Kiss Me More (feat. SZA) by Doja Cat 236,820"
## 6 "Life (Sun luo) by Cledos, BEHM 224,839"
## 7 "Astronaut In The Ocean by \\Viasked VVolf 202,630"
## 8 "Frida by BEHM 200,910"
## 9 "Hyvat hautajaiset by Pyhimys, Eino Grén 196 , 586"
## 10 "Ne voi liittyy (feat. BIZI) by costee 194,852"
## 11 "Friday (feat. Mufasa & Hypeman) - Dopamine Re-Edit by Riton, Nightcrawilers~
## 12 "Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x3), Bugzy Malone, Buni, Fivio F~
## 13 "Wellerman - Sea Shanty / 220 KID x Billen Ted Remix by Nathan Evans 182,353"
## 14 "Levitating (feat. DaBaby) by Dua Lipa 180 , 922"
## 15 "Prinsessa by Etta 175.544"
## 16 "Hei rakas by BEH!V/ 168,578"
## 17 "Peaches (feat. Daniel Caesar & Giveon) by Justin Bieber 167 .833"
## 18 "Kaipaan sua (feat. Boyat & Samuli Heimo) by Keko Salate 158 , 543"Alright, now for the fun part, our old pal regex.
10. Split the data into 3 columns using regex and tidyr’s extract()
We choose the column (chr) we want to split up, then tell extract() the target column names, then the regex part, which is basically saying that let’s put everything before the word by to the first column ([^:]+), let’s put everything after the word by to the second columnn ([^-]+), but any two groups of numbers (that have , or . in the middle) that are at the end of the row, should be put to the third column (\d+.[,.].\d+$).
And yes, those empty characters matter. Without them, the cells would have those empty characters before or after the values we want.
png_2_regex_tbl <- extract(png_2_merged_tbl,
chr,
into = c('track', 'artist', 'streams'),
'([^:]+) by ([^-]+) (\\d+.[,.].\\d+$)',
convert = TRUE)
png_2_regex_tbl
## # A tibble: 18 x 3
## track artist streams
## <chr> <chr> <chr>
## 1 MONTERO (Call Me By Your Name) "Li! Nas x" 275,091
## 2 Dark Side "Blind Channe!" 260.403
## 3 Pettaja "SANN|" 255,770
## 4 Piilotan mun kyyneleet "Haloo Helsinki!" 238,089
## 5 Kiss Me More (feat. SZA) "Doja Cat" 236,820
## 6 Life (Sun luo) "Cledos, BEHM" 224,839
## 7 Astronaut In The Ocean "\\Viasked VVolf" 202,630
## 8 Frida "BEHM" 200,910
## 9 Hyvat hautajaiset "Pyhimys, Eino Grén" 196 , 5~
## 10 Ne voi liittyy (feat. BIZI) "costee" 194,852
## 11 Friday (feat. Mufasa & Hypeman) - Dopamine R~ "Riton, Nightcrawiler~ 186,470
## 12 Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x~ "eS Tion Wayne, Russ ~ 182,369
## 13 Wellerman - Sea Shanty / 220 KID x Billen Te~ "Nathan Evans" 182,353
## 14 Levitating (feat. DaBaby) "Dua Lipa" 180 , 9~
## 15 Prinsessa "Etta" 175.544
## 16 Hei rakas "BEH!V/" 168,578
## 17 Peaches (feat. Daniel Caesar & Giveon) "Justin Bieber" 167 .833
## 18 Kaipaan sua (feat. Boyat & Samuli Heimo) "Keko Salate" 158 , 5~Almost there! Time for the final cleanup with some tidyverse magic!
11. Final cleanup with tidyverse goodness
I won’t go through everything in detail, but in the next chunk of code, we first clean up the streams column and make it numeric.
Then we use case_when() (such a great function!) to correct any spelling mistakes left.
We add the rank column and populate it with row_number() (that’s why we needed to use arrange() earlier).
And finally, we use select to order the columns nicely.
png_2_final_tbl <- png_2_regex_tbl %>%
mutate(
streams = png_2_regex_tbl$streams %>%
str_remove_all(pattern = regex("[ ., ]")) %>% as.numeric(),
track = case_when(
track == "Pettaja" ~ "Pettäjä",
track == "Hyvat hautajaiset" ~ "Hyvät hautajaiset",
TRUE ~ track),
artist = case_when(
artist == "Li! Nas x" ~ "Lil Nas X",
artist == "Blind Channe!" ~ "Blind Channel",
artist == "SANN|" ~ "SANNI",
artist == "\\Viasked VVolf" ~ "Masked Wolf",
artist == "Pyhimys, Eino Grén" ~ "Pyhimys, Eino Grön",
artist == "Riton, Nightcrawilers" ~ "Riton, Nightcrawlers",
artist == "BEH!V/" ~ "BEHM",
artist == "Keko Salate" ~ "Keko Salata",
str_detect(artist, "Tion Wayne") ~ "Tion Wayne, Russ Millions",
TRUE ~ artist),
rank = row_number()
) %>%
select(artist, track, rank, streams)
png_2_final_tbl
## # A tibble: 18 x 4
## artist track rank streams
## <chr> <chr> <int> <dbl>
## 1 Lil Nas X MONTERO (Call Me By Your Name) 1 275091
## 2 Blind Channel Dark Side 2 260403
## 3 SANNI Pettäjä 3 255770
## 4 Haloo Helsinki! Piilotan mun kyyneleet 4 238089
## 5 Doja Cat Kiss Me More (feat. SZA) 5 236820
## 6 Cledos, BEHM Life (Sun luo) 6 224839
## 7 Masked Wolf Astronaut In The Ocean 7 202630
## 8 BEHM Frida 8 200910
## 9 Pyhimys, Eino Gr~ Hyvät hautajaiset 9 196586
## 10 costee Ne voi liittyy (feat. BIZI) 10 194852
## 11 Riton, Nightcraw~ Friday (feat. Mufasa & Hypeman) - Dopamine R~ 11 186470
## 12 Tion Wayne, Russ~ Body (Remix) [feat. ArrDee, E1 (3x3), ZT (3x~ 12 182369
## 13 Nathan Evans Wellerman - Sea Shanty / 220 KID x Billen Te~ 13 182353
## 14 Dua Lipa Levitating (feat. DaBaby) 14 180922
## 15 Etta Prinsessa 15 175544
## 16 BEHM Hei rakas 16 168578
## 17 Justin Bieber Peaches (feat. Daniel Caesar & Giveon) 17 167833
## 18 Keko Salata Kaipaan sua (feat. Boyat & Samuli Heimo) 18 158543Now all that’s left to do is to write the excel file.
12. Create Excel file with writexl
write_xlsx(png_2_final_tbl, "index_files/excel_from_pdf_with_image_2.xlsx")
# You should change the file path to suit your needs
fig. 2 - Extract from the final Excel file
Conclusion
I can’t help but go back to the quote we started this journey with:
Keep in mind that OCR (pattern recognition in general) is a very difficult problem for computers. Results will rarely be perfect and the accuracy rapidly decreases with the quality of the input image. But if you can get your input images to reasonable quality, Tesseract can often help to extract most of the text from the image.
I feel like everything that was said in that quote was realised during this experiment. And even if I had to use some manual data cleaning to get to the final excel file, I’m still super impressed by both tesseract and magick. This was the first time using them both and we still got pretty far!
Now it’s time to end this mini-trilogy. Let’s see what I come up with next. It might be another test run with a cool package I want to learn to use or it might be more generally about my learning journey.
If you’ve read this far, thanks for your time and interest! If you have any questions or comments, don’t hesitate to contact me on LinkedIn (since I still haven’t managed to add the Disqus module for comments, but I’m working on it)!
Updated: 5 June, 2021
Created: 5 June, 2021